咨询电话: 020-88888888

如何批量下载抖音用户所有视频?_2!
发布于 2024-01-02 19:58 阅读()
首先声明该方法仅供个人学习交流使用,严禁非法获利。
- 获取用户主页分享链接:用户主页右上角点开,获取分享链接
得到类似分享链接:在抖音,记录美好生活!https://v.douyin.com/eSN7g1c/
- 运行程序,批量下载该用户无水印视频:
- 获取用户抖音昵称,并创建同名文件夹存放视频
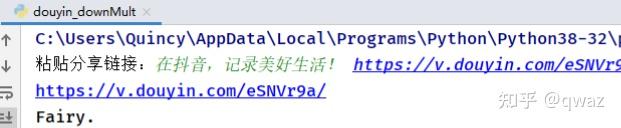
- 校验用户所有时间段是否发布过视频,校验数量为0则跳过,不为0则进行下载
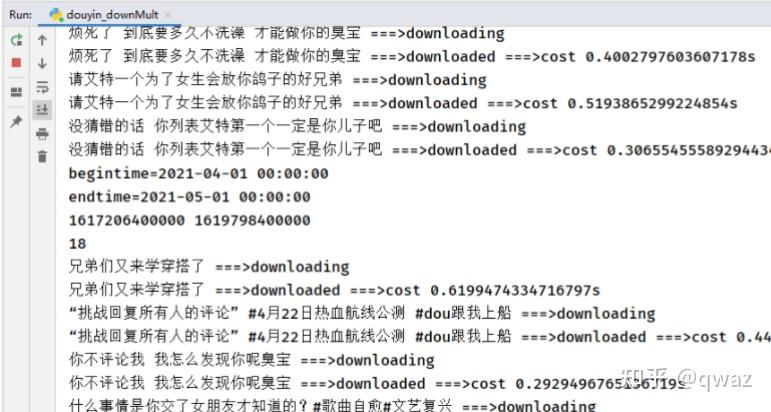
- 下载并保存,数量和用户主页视频数量一致

- 验证一下,确实无水印,bingo!

- 分享程序思路
1.根据用户页面分享的链接提取url2.根据url来进行请求,通过禁用重定向来获取headers['location'],再从中提取sec_id3.拼接该用户所有视频列表请求url,然后在下载保存即可。下面给出一个请求参数示例:params={ 'sec_uid' : 'MS4wLjABAAAAbtSlJK_BfUcuqyy8ypNouqEH7outUXePTYEcAIpY9rk', #每个用户不同 'count' : '200', #每次请求返回视频list中视频条数,不建议太大 'min_cursor' : '1612108800000',#用户视频开始时间,带毫秒的时间戳 'max_cursor' : '1619251716404',#用户视频结束时间,带毫秒时间戳 'aid' : '1128',#未知参数,可有可无 '_signature' : 'PtCNCgAAXljWCq93QOKsFT7QjR' #签名值,直接从请求参数里面复制一个就能一直用}
- 关键代码:
1).提取分享链接中的url
string=input('粘贴分享链接:')
shroturl=re.findall('[a-z]+://[\\S]+', string, re.I|re.M)[0]2).请求上述url,禁用重定向获取location的value,在正则提取出sec_id
startpage=requests.get(url=shroturl, headers=headers, allow_redirects=False)
location=startpage.headers['location']
sec_uid=re.findall('(?<=sec_uid=)[a-z,A-Z,0-9, _, -]+', location, re.M|re.I)[0]3).拼接请求用户信息url,获取用户昵称,也可以获取其他信息,这里只取昵称
getname=requests.get(url='https://www.iesdouyin.com/web/api/v2/user/info/?sec_uid={}'.format(sec_uid), headers=headers).text
userinfo=json.loads(getname)
name=userinfo['user_info']['nickname']4).创建用户昵称同名文件夹,切换到该路径下
Path=name
if os.path.exists(path=Path)==False:
os.mkdir(path=Path)
else:
print('directory exist')
os.chdir(path=Path)5).视频时间戳生成,原本可以直接使用一个大跨度的时间段,但是在测试中发现时间跨度太大的话,下载的视频数量会变少,多次测试后确定以1个月为间隔,年份从2018到2021,基本上也没有更早的视频了吧
year=('2018','2019','2020','2021')
month=('01','02','03','04','05','06','07','08','09','10','11','12')
timepool=[x+'-'+y+'-01 00:00:00' for x in year for y in month ]
print(timepool)
k=len(timepool)
for i in range(k) :
if i < k-1 :
print('begintime='+timepool[i])
print('endtime='+timepool[i+1])
beginarray=time.strptime(timepool[i], "%Y-%m-%d %H:%M:%S")
endarray=time.strptime(timepool[i+1], "%Y-%m-%d %H:%M:%S")
t1=int(time.mktime(beginarray) * 1000)
t2=int(time.mktime(endarray) * 1000)
print(t1,t2)6).到这里,params里面的参数都拿到了,直接拼接视频列表url,把返回结果存入json中。
awemeurl='https://www.iesdouyin.com/web/api/v2/aweme/post/?'
awemehtml=requests.get(url=awemeurl, params=params, headers=headers).text
data=json.loads(awemehtml)7).直接从json中提取我们要的内容{“视频数量”,“视频title”,“无水印视频url”},然后还等啥,下载吧
awemenum=len(data['aweme_list'])
print(awemenum)
for i in range(awemenum):
videotitle=data['aweme_list'][i]['desc'].replace("?", "").replace("\\"","").replace(":","")
videourl=data['aweme_list'][i]['video']['play_addr']['url_list'][0]
start=time.time()
print('{}===>downloading'.format(videotitle))
with open(videotitle+'.mp4', 'wb') as v:
try:
v.write(requests.get(url=videourl, headers=headers).content)
end=time.time()
cost=end - start
print('{}===>downloaded===>cost{}s'.format(videotitle, cost))
except Exception as e:
print('download error')import requests
import json
import os
import time
import re
"""
1.根据用户页面分享的字符串提取短url
2.根据短url加上302获取location,提取sec_id
3.拼接视频列表请求url
params={
'sec_uid' : 'MS4wLjABAAAAbtSlJK_BfUcuqyy8ypNouqEH7outUXePTYEcAIpY9rk',
'count' : '200',
'min_cursor' : '1612108800000',
'max_cursor' : '1619251716404',
'aid' : '1128',
'_signature' : 'PtCNCgAAXljWCq93QOKsFT7QjR'
}
"""
headers={
"user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Mobile Safari/537.36"
}
# string='在抖音,记录美好生活! https://v.douyin.com/ekkTsYw/'
string=input('粘贴分享链接:')
shroturl=re.findall('[a-z]+://[\\S]+', string, re.I|re.M)[0]
print(shroturl)
startpage=requests.get(url=shroturl, headers=headers, allow_redirects=False)
location=startpage.headers['location']
sec_uid=re.findall('(?<=sec_uid=)[a-z,A-Z,0-9, _, -]+', location, re.M|re.I)[0]
getname=requests.get(url='https://www.iesdouyin.com/web/api/v2/user/info/?sec_uid={}'.format(sec_uid), headers=headers).text
userinfo=json.loads(getname)
name=userinfo['user_info']['nickname']
print(userinfo['user_info']['nickname'])
Path=name
if os.path.exists(path=Path)==False:
os.mkdir(path=Path)
else:
print('directory exist')
os.chdir(path=Path)
"""new function"""
year=('2018','2019','2020','2021')
month=('01','02','03','04','05','06','07','08','09','10','11','12')
timepool=[x+'-'+y+'-01 00:00:00' for x in year for y in month ]
print(timepool)
k=len(timepool)
for i in range(k) :
if i < k-1 :
print('begintime='+timepool[i])
print('endtime='+timepool[i+1])
beginarray=time.strptime(timepool[i], "%Y-%m-%d %H:%M:%S")
endarray=time.strptime(timepool[i+1], "%Y-%m-%d %H:%M:%S")
t1=int(time.mktime(beginarray) * 1000)
t2=int(time.mktime(endarray) * 1000)
print(t1,t2)
params={
'sec_uid' : sec_uid,
'count' : 200,
'min_cursor' : t1,
'max_cursor' : t2,
'aid' : 1128,
'_signature' : 'PtCNCgAAXljWCq93QOKsFT7QjR'
}
awemeurl='https://www.iesdouyin.com/web/api/v2/aweme/post/?'
awemehtml=requests.get(url=awemeurl, params=params, headers=headers).text
data=json.loads(awemehtml)
# print(data)
# print(type(data))
awemenum=len(data['aweme_list'])
print(awemenum)
for i in range(awemenum):
videotitle=data['aweme_list'][i]['desc'].replace("?", "").replace("\\"","").replace(":","")
videourl=data['aweme_list'][i]['video']['play_addr']['url_list'][0]
start=time.time()
print('{}===>downloading'.format(videotitle))
with open(videotitle+'.mp4', 'wb') as v:
try:
v.write(requests.get(url=videourl, headers=headers).content)
end=time.time()
cost=end - start
print('{}===>downloaded===>cost{}s'.format(videotitle, cost))
except Exception as e:
print('download error')新闻资讯
 针对弱势群体利用AI网暴,从重 TOP1
针对弱势群体利用AI网暴,从重 TOP1 -
2
 虎扑体育NBA滚动新闻(nba 07-01
虎扑体育NBA滚动新闻(nba 07-01 -
3
 老板军师日记3:餐饮老板的困惑 07-01
老板军师日记3:餐饮老板的困惑 07-01 -
4
 抖音钱包怎么提现到微信?抖音支 07-01
抖音钱包怎么提现到微信?抖音支 07-01 -
5 写作相关-----电路专业术语 07-01
-
6
 TechWeb武汉 | 罗知: 07-01
TechWeb武汉 | 罗知: 07-01 -
7
 房地产业转型需要构建怎样的长效 07-01
房地产业转型需要构建怎样的长效 07-01 -
8解困房 07-01
-
9Lisa在疯马秀上一脱,让女团 07-01