咨询电话: 020-88888888

关于深度学习的优化器选择!
发布于 2024-03-04 13:18 阅读()
优化器的种类有很多,概括起来常用的有五类:
- 随机梯度下降(SGD, stochastic gradient descent)
- SGDM(加入了一阶动量)
- AdaGrad(加入了二阶动量)
- RMSProp
- Adam
以下是我跑的五种优化器模型画出来的loss和acc曲线对比图
在lr=0.1,epoch=500的训练条件下,5种优化器都可以成功收敛。
在训练时间方面,Rmsprop训练耗时较短,比耗时最长的Sgdm优化器快将近7秒;在训练过程方面,Adam优化器表现较好,在60到80轮的时候已基本接近最低值,明显优于其他优化器,而Sgd、Sgadm以及Adagrad在前100轮训练中表现相似,只有Rmsprop数据震荡较大;
loss图对比:Sgd、Sgdm、Adagrad三种优化器的loss图差别不大,Rmsprop优化器因为lr设置较大出现锯齿状下降,说明当学习率过大时优化不稳定,Adam优化器的loss图下降的最快。
Acc图对比:Sgd、Sgdm和Rmsprop的Acc图在刚开始一段都直接上升到某一值才慢慢增加,而Adagrad的Acc图并没有出现相似情况,Rmsprop又出现了锯齿状的上升现象,并在Acc达到1后出现再次下降的情况,Adam的Acc上升的最快,几乎是直线上升。
total_time对比:Sgd的训练时间最长,Adam第二,其他三个相差不多。
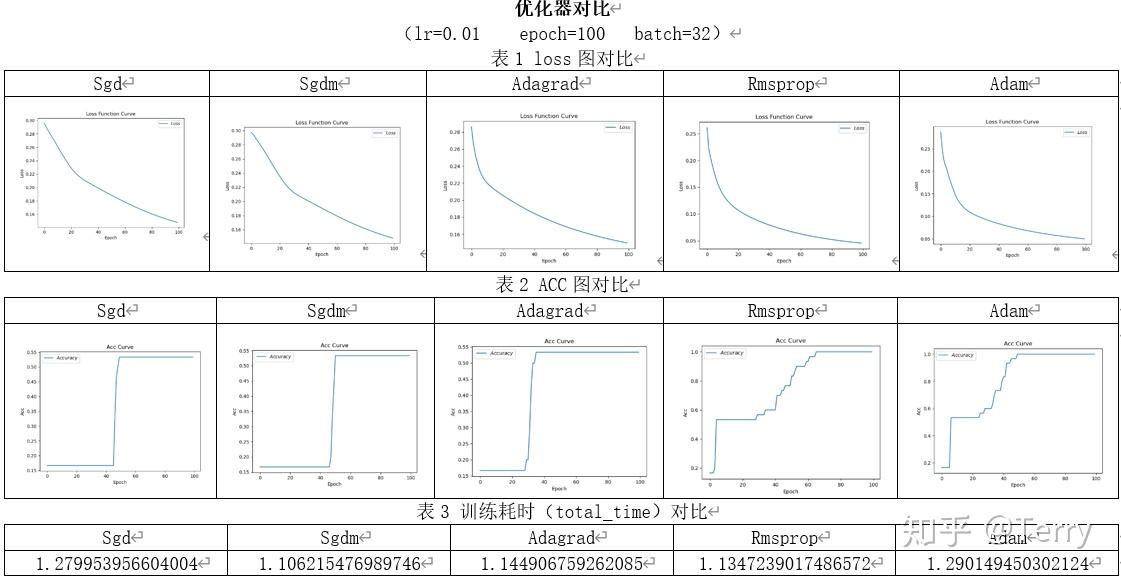
在lr=0.01,epoch=100的训练条件下,只有Rmsprop和Adam成功收敛。
在训练时间方面,Sgd一骑绝尘,比训练时间最长的Rmsprop优化器快了将近0.8秒;在训练过程方面,Adagrad优化器表现较好,前20轮训练中训练效果明显,loss值下降较快。loss图像Adamgrad、Rmsprop和Adam较为光滑;
loss图对比:由于学习率的下降,Rmsprop的loss图没有出现锯齿状,五个优化器的loss图相差不大。
Acc图对比:Rmsprop在60轮左右完全收敛,Adam在50轮左右完全收敛。
total_time对比:收敛的两个优化器中Rmsprop的总耗时相对较短。
综上,通过简单实验对比。在数据集较大的情况下,Adam优化器收敛速度较快,效果较好;在数据集较小的时候,Adagrad优化器收敛速度较快,效果较好。
但是对于初学者的忠告:
1. 首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑SGD+Nesterov Momentum或者 Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam)
2. 选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。
3. 充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
4. 根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进 行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
5. 先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系 不大。(The mathematics of stochastic gradient descent are amazingly independent of the training set size. In particular, the asymptotic SGD convergence rates are independent from the sample size.)因此可以先用一个具有代表性的小数据集进行实验,测试 一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
6. 考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。
7. 充分打乱数据集(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出 现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。在每一轮迭代后对训 练数据打乱是一个不错的主意。
8. 训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。 对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数 据的监控是为了避免出现过拟合。
9. 制定一个合适的学习率衰减策略。可以使用分段常数衰减策略,比如每过多少个epoch就衰减一 次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习 率。
10. Early stopping。如Geoff Hinton所说:“Early Stopping是美好的免费午餐”。你因此必须在训 练的过程中时常在验证集上监测误差,在验证集上如果损失函数不再显著地降低,那么应该提前结 束训练。
11. 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局 部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不 同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
算法没有好坏,最适合数据的才是最好的,永远记住:No free lunch theorem!
新闻资讯
 去美国读研究生,这20个问题你 TOP1
去美国读研究生,这20个问题你 TOP1 -
2
 美高党必读:一篇优秀的英文版推 06-01
美高党必读:一篇优秀的英文版推 06-01 -
3
 推荐信中的开头与结尾最佳实践 06-01
推荐信中的开头与结尾最佳实践 06-01 -
4 留学建筑学专业去哪个国家比较好 06-01
-
5 医学生出国途径 06-01
-
6
 艺术出国留学国家哪个比较好?_ 06-01
艺术出国留学国家哪个比较好?_ 06-01 -
7
 美术生可以考什么大学 美术生可 06-01
美术生可以考什么大学 美术生可 06-01 -
8
 俄罗斯留学美术条件要求 06-01
俄罗斯留学美术条件要求 06-01 -
9
 新西兰创业移民有哪些类型 06-01
新西兰创业移民有哪些类型 06-01