咨询电话: 020-88888888

机器学习与优化算法的关系?!
发布于 2024-04-29 04:11 阅读()
在处理一个非凸优化问题时,我们可以通过将其变成凸优化,然后不断迭代,最终得到stationary point。
如今机器学习不断发展,一些论文采用了Deep learning、Deep reinforcement learning等等方式进行求解优化问题。
Deep learning的思路是,首先给定一些输入,采用常用的优化算法进行求解,得到输出。然后采用神经网络构建输入输出之间的非线性关系。
Deep reinforcement learning的思路是将输入值等作为state,目标函数作为reward,优化变量作为action进行迭代。
我想问:除了这两种方式之外,机器学习还可以怎么应用在优化问题上面?
我理解deep learning是优化算法的一种应用。机器学习主要解决的是优化问题,它不一定是deep learning,但是它一般也都用到了优化算法。
目前deep learning主要是基于梯度的优化,无论是drl还是dl。dlr和dl只是确定loss函数和建模方式有所不同,drl是基于贝尔曼方程对马尔可夫决策过程建模,dl一般是用最小二乘或者最大似然估计对优化问题进行建模。基于梯度的优化方法在优化理论中一般归为无约束优化。而人工神经网络本身就是优化问题的参数的表达形式。
我们知道凸问题在梯度方法下会得到全局最优解,但是神经网络通常都是非凸的,所以梯度方法通常得不到全局最优解,实际上一般它会收敛到一些高维空间的类平面上。采用梯度方法的原因是它计算简单快速,而随机梯度优化在实践中被证明具有较好的泛化性。
本次讲解,两个比较重要的话题:优化问题 / 机器学习。
在约束条件下,达成目标的问题。
解决办法有很多,其中,比较重要的一个为动态规划(是一种思想,思维类型,不使用动态规划也能解决,但是不太方便)。
例如,有一根木棍,不同长度,价格不等,现在有一个木棍,如何分割,使得利益最大化?
计算机的一个好处,就是可以进行穷尽列举(代码已更新至github)。
- 所有的动态规划问题,都包含以下问题:
- 可以被分解成子问题
- 存在子问题的重复
- 需要解析solution
1970-1990s,动态规划问题,其实是图和树(存在子问题)的算法优化,占据主流(因为可以加速解决),应用在图像分割/识别,文本分类/识别(李开复解决语言识别问题,就是拆分成了语法树)。
- 动态规划局限性,有可能会遇到如下情况:
- 限制条件特别多
- 问题分解太复杂
- 子问题拆解极多
由此,提出了机器学习的方法。
1990s之后,email兴起,垃圾/诈骗邮件(成本低)大量存在,产业很大。
随之出现了付费,拦截垃圾邮件。
垃圾邮件公司,为了绕开公司的正当防卫(使用了语法树),产开了很长时间的斗争。
然而,邮件可以变,正义的力量无法攻破邪恶的力量。
哈佛大学,用了基于统计的文本贝叶斯方法,判断垃圾邮件,不用人工去分析。根据历史出现的词,判断新邮件是垃圾邮件的概率是多少?可以拦截大部分垃圾邮件。而且可以自动更新。根据,原来的信息,自动的提炼出信息。从此,将这类解决问题的方法,被称之为“机器学习”。
如果一个事物,无法被量化,那么就无法被分析。例如,刻画一个人,就需要有他的身高,体重,年龄,收入等。
如果人1和人2对应的向量相近,则可知,这两个人相似。
- 回归问题
- 分类问题(2分类,多分类)
- 序列问题(输出多个决策行动)
- 排序问题(输入1234,输出2143)
回归:遗传学/生物学概念,即: 群体的下一代特征,会回归于平均值。也就是说,回归是在拟合整体的平均值。
深度学习是一种机器学习;机器学习是一种解决人工智能的方法。
监督学习:机器半自动的获取f(函数),这个函数有标准答案的,是一个有对错的方法。
非监督学习:也叫做聚类(分类),没有标准答案(不太好量化,只能作为参考)。
观察数据→提取特征→将数据变成向量→进行学习(根据老向量,得到一个函数)→使用新函数,预测新数据的label
监督学习:训练数据的x和y,都给模型。
非监督学习:只提供x。
监督学习中,求解函数参数的方法。
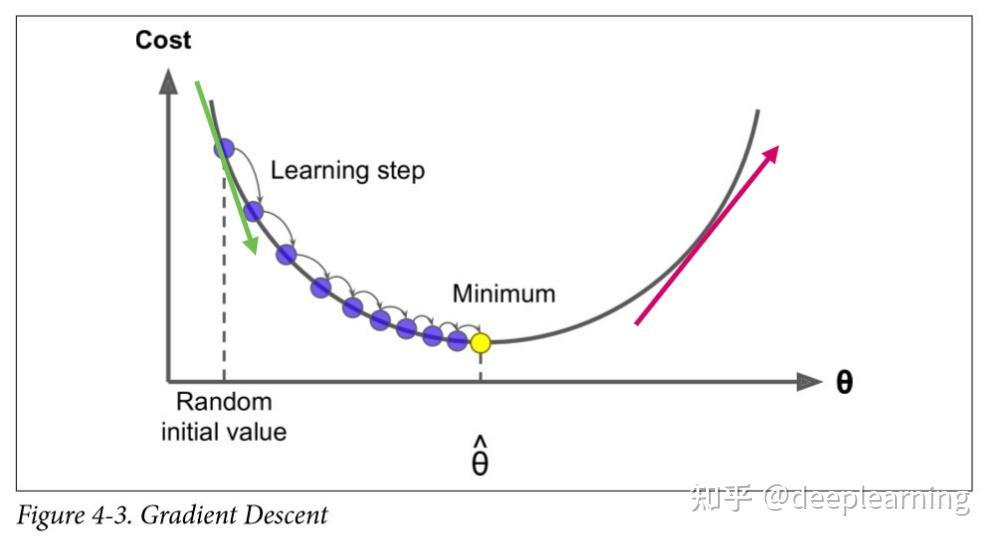
从图中可得,若:
初始点θ在左侧,则该点处的斜率( )< 0 ,要想loss达到最小值,θ应该增大。
初始点θ在右侧,则该点处的斜率( )> 0 ,要想loss达到最小值,θ应该减小。
所以,可得梯度下降的参数更新公式:
如果不加α,那么当很快接近最小值时,就会错过最小值,跑偏了。
同理,参数b的更新也是一样的。
针对部分违禁品的售卖,会使用一些行业“黑话”为了找到这些商品,可以进行如下处理:
- 【观察数据】选取部分淘宝商品描述;
- 【提取特征,并向量化】将文本向量化(例如,最简单的tf-idf);
- 【学习(无监督)】对文本进行聚类,文本接近的词,归为一类;
- 按照已知暗语,定位商品类别。
- 获得该商品类别中,词汇频率远高于正常词汇分布的单词,这些单词就很有可能是“黑话”。
算法原理步骤:
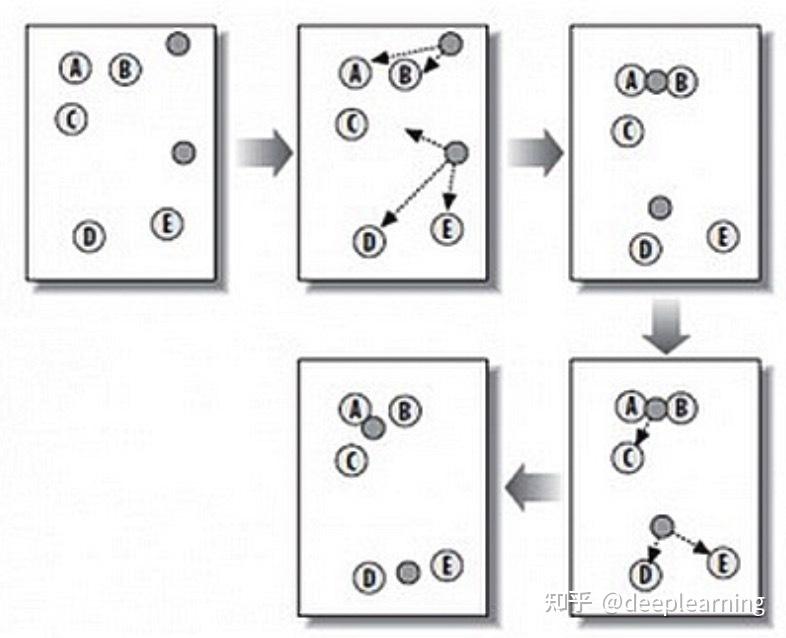
K:K个初始点,K个组,K个类别。
means:求平均值。
K-maen 缺点:计算时间复杂度较高;结果受初始值选取的影响较大。
注意:
- 算法工程师,最重要的是,具备能力:能把实际问题抽象成算法问题,并得到答案。
- 单靠机器学习很难解决完整项目,只是整个项目过程中的一部分。
在本节中,我们讲讨论优化与深度学习之间的关系以及在深度学习中使用优化的挑战。对于深度学习问题,我们通常会先定义损失函数。一旦我们有了损失函数,我们就可以使用优化算法来尝试最小化损失。在优化中,损失函数通常被称为优化问题的目标函数。按照传统和惯则,大多数优化算法都关注的是最小化。若我们需要最大化目标,那么只需要要在目标函数前加符号即可
尽管优化提供了一种最大限度地减少深度学习损失函数的方法,但实质上,优化和深度学习的目标是根本不同的。前者主要关注的是最小化目标,后者则关注在给定的有限数据的情况下寻找合适的模型。
两个目标之间的区别,例如,训练误差和泛化误差通常不同;由于优化算法的目标函数通常是基于训练数据集的损失函数,因此优化的目标是减少训练误差。但是,深度学习的目标是减少泛化误差,为了实现后者,除了使用优化算法来减少训练误差之外,我们还需要注意过拟合
%matplotlib inline
import numpy as np
import torch
from mpl_toolkits import mplot3d
from d2l import torch as d2l为了说明上述不同的目标,让我们考虑经验风险和风险
- 经验风险:训练数据集的平均损失
- 风险:整个数据群的预期损失
下面我们定义了两个函数;风险函数f和经验风险函数g,假设我们只有有限量的训练数据。因此,这里的g不如f平滑
def f(x):
return x * torch.cos(np.pi * x)
?
def g(x):
return f(x) + 0.2 * torch.cos(5 * np.pi * x)下图说明,训练数据集的最低经验误差可能与最低风险(泛化误差)不同
def annotate(text,xy,xytext):
d2l.plt.gca().annotate(text,xy=xy,xytext=xytext,arrowprops=dict(arrowstyle='->'))
x = torch.arange(0.5,1.5,0.01)
d2l.set_figsize((4.5,2.5))
d2l.plot(x,[f(x),g(x)],'x','risk')
annotate('min of \
empirical risk',(1.0,-1.2),(0.5,-1.1))
annotate('min of risk',(1.1,-1.05),(0.95,-0.5))?
在本章中,我们讲特别关注优化算法在最小化目标函数方面的性能,而不是模型的泛化误差。
在3.1中我区分了优化问题中的解析解和数值解。在深度学习中,大多数目标函数都很复杂,没有解析解。相反,我们必须用数值优化算法,本章的优化算法都属于数值优化算法
深度学习优化存在许多挑战。其中一些最令人烦恼的是局部最小值、鞍点和梯度消失

x = torch.arange(-1.0,2.0,0.01)
d2l.plot(x,[f(x),],'x','f(x)')
annotate('local minimum', (-0.3, -0.25), (-0.77, -1.0))
annotate('global minimum', (1.1, -0.95), (0.6, 0.8))?
深度学习模型的目标函数通常由许多局部最优解。当优化问题的数值解接近局部最优值时,随着目标函数解的梯度接近或变为零,通过最终迭代获得的数值解可能仅使目标函数局部最优,而不是全局最优。只有一定程度的噪声可能会使参数超出局部最小值。
事实上,这是小批量随机梯度下降的有利特性之一,在这种情况下,小批量上梯度的自然变化能够将参数从局部极小值中移出
除了局部最?值之外,鞍点也是梯度消失的另?个原因。鞍点(saddle point)是指函数的所有梯度都消失但既不是全局最?值也不是局部最?值的任何位置。考虑这个函数f(x)=x^3。它的?阶和?阶导数在x=0时消失。这时优化可能会停?,尽管它不是最?值
x = torch.arange(-2.0,2.0,0.01)
d2l.plot(x,[x**3],'x','f(x)')
annotate('saddle point',(0,-0.2),(-0.52,-5.0))?
如下例所示,较高维度的鞍点甚至更加隐蔽,考虑整个函数$f(x,y)=x^2-y^2$。它鞍点为(0,0)。这是关于y的最大值,也是关于x的最小值。此外,它看起来像马鞍,这就是这个数学属性的名字由来
x,y = torch.meshgrid(
torch.linspace(-1.0,1.0,101),torch.linspace(-1.0,1.0,101))
?
z = x**2 - y**2
?
ax = d2l.plt.figure().add_subplot(111,projection='3d')
ax.plot_wireframe(x,y,z,**{'rstride':10,'cstride':10})
ax.plot([0],[0],[0],'rx')
ticks = [-1,0,1]
d2l.plt.xticks(ticks)
d2l.plt.yticks(ticks)
ax.set_zticks(ticks)
d2l.plt.xlabel('x')
d2l.plt.ylabel('y')
C:\\Users\\20919\\anaconda3\\envs\\d2l\\lib\\site-packages\\torch\\functional.py:478: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at C:\\actions-runner\\_work\\pytorch\\pytorch\\builder\\windows\\pytorch\\aten\\src\\ATen\\native\\TensorShape.cpp:2895.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]Text(0.5, 0.5, 'y')?
我们假设函数的输入是k维向量,其输出是标量,因此其Hessian(黑塞)矩阵将有k特征值。函数的解决方案可以是局部最小值、局部最大值或函数梯度为零的位置处的鞍点:
- 当函数在零梯度位置处的Hessian矩阵的特征值全部为正值时,我们有该函数的局部最?值
- 当函数在零梯度位置处的Hessian矩阵的特征值全部为负值时,我们有该函数的局部最?值
- 当函数在零梯度位置处的Hessian矩阵的特征值为负值和正值时,我们对函数有?个鞍点
对于高纬度问题,至少部分特征值为负的可能性相当高。这使得鞍点比局部最小值更有可能。我们将在下一节介绍凸性时讨论这种情况的一些例外情况
凸函数时Hessian函数的特征值永远不是负值的函数。不幸的是,大多数深度学习问题并不属于这个类别,尽管如此,它还是研究优化算法的一个很好工具

x = torch.arange(-2.0,5.0,0.01)
d2l.plot(x,[torch.tanh(x)],'x','f(x)')
annotate('vanishing gradient',(4,1),(2,0.0))?
正如我们所看到的那样,深度学习的优化充满挑战。幸运的是,有一系列强大的算法表现良好,即使对于初学者也很容易使用。此外,没有必要找到最佳的解决方案,局部最优解或其近似解仍然非常有用
- 最小化训练误差并不能保证我们找到最佳的参数集来最小化泛化误差
- 优化问题可能有许多局部最小值
- 问题可能有更多的鞍点,因为通常问题不是凸的
- 梯度消失可能会导致优化停滞,重参数化通常会有所帮助,对参数进行良好的初始化也可能是有益的
使用寻优算法来优化机器学习的超参数,能够省去手动网格所搜的时间,同时找到最优的超参数。
以遗传算法与随机森林算法为例,代码如下:
#调库,数据集使用鸢尾花数据集
from sko.GA import GA
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
#读取数据,打印数据形状
data = load_iris()
X = data.data
Y = data.target
print(X.shape,Y.shape)
#将随机森林写到函数里,设置森林数量与森林深度两个参数
def rc(P):
n_estimators,max_depth = P
# 创建随机森林分类器
clf = RandomForestClassifier(n_estimators=int(n_estimators), max_depth=int(max_depth))
clf.fit(X,Y)
score = clf.score(X, Y)
accuracy = score
# 返回负的准确率,因为遗传算法追求最小化问题
return -accuracy
#森林数量为1,深度为10,试运行一下
rc([1,10])
#定义遗传算法,维度为2,森林上下限为[10,100],深度上下限为[1,10]
ga = GA(func=rc, n_dim=2, size_pop=50, max_iter=100, lb=[10,1,], ub=[100,10])
best_X, best_Y = ga.run()
print(best_X, -best_Y)#打印最优森林数、最优深度,以及最优准确率新闻资讯
 上海农商银行推“世界白金鑫卡” TOP1
上海农商银行推“世界白金鑫卡” TOP1 -
2
 强化业绩补偿监管,支持环保企业 05-15
强化业绩补偿监管,支持环保企业 05-15 -
3
 利率大幅单边上行可能性不大 05-15
利率大幅单边上行可能性不大 05-15 -
4
 商标注册的八大作用 05-11
商标注册的八大作用 05-11 -
5
 从党章的学思践悟中汲取前行伟力 07-05
从党章的学思践悟中汲取前行伟力 07-05 -
6 化学反应工程 07-05
-
7
 劲爆串烧 07-05
劲爆串烧 07-05 -
8 幸运破解器最新版_2 07-05
-
9 深入解析:OLTP与OLAP的 07-05